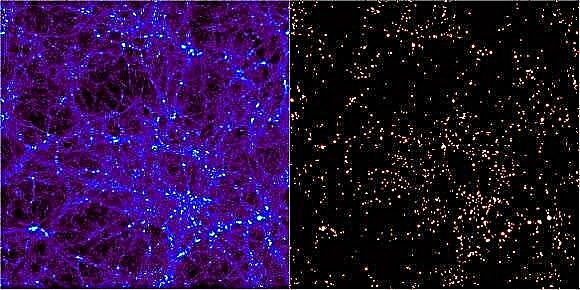
Един от успехите на ΛCDM модела на Вселената е възможността моделите да създават структури с мащаби и разпределения, подобни на тези, които разглеждаме в сп. „Космос“. Докато компютърните симулации могат да пресъздадат числови вселени в кутия, интерпретирането на тези математически приближения е предизвикателство само по себе си. За да идентифицират компонентите на симулираното пространство, астрономите трябваше да разработят инструменти за търсене на структура. Резултатите са близо 30 независими компютърни програми от 1974 г. Всяка обещава да разкрие формиращата се структура във Вселената, като намери региони, в които се образуват ореоли на тъмната материя. За да се тестват тези алгоритми, през май 2010 г. беше организирана конференция в Мадрид, Испания, озаглавена „Haloes going MAD“, в която 18 от тези кодове бяха подложени на тест, за да се види колко добре са подредени.
Числените симулации за вселени, като известната симулация на хилядолетието, започват с нищо повече от „частици“. Макар че те бяха безспорно малки в космологичен мащаб, такива частици представляват петна от тъмна материя с милиони или милиарди слънчеви маси. С течение на времето им се позволява да си взаимодействат помежду си, следвайки правила, които съвпадат с най-доброто ни разбиране на физиката и същността на такава материя. Това води до развиваща се вселена, от която астрономите трябва да използват сложните кодове, за да намерят конгломерациите на тъмната материя, вътре в които ще се образуват галактики.
Един от основните методи, които подобни програми използват, е да търсят малки наднормено тегло и след това да отглеждат сферична обвивка около нея, докато плътността не падне до нищожен фактор. След това повечето ще подрязват частиците в обема, които не са гравитационно обвързани, за да се уверят, че механизмът за откриване не е застъпил само на кратко, преходно клъстеризиране, което ще се разпадне във времето. Други техники включват търсене на други фазови пространства за частици със сходна скорост във всички близости (знак, че те са се свързали).
За да се сравни как се е справил всеки от алгоритмите, те бяха подложени на два теста. Първият, включващ поредица от умишлено създадени ореоли от тъмна материя с вградени под-ореоли. Тъй като разпределението на частици е било умишлено поставено, изходът от програмите трябва правилно да намира центъра и размера на ореолите. Вторият тест беше пълноценна симулация на Вселената. При това реалното разпределение не би било известно, но чистият размер би позволил да се сравняват различни програми в един и същ набор от данни, за да се види доколко по същия начин интерпретират общ източник.
И в двата теста обикновено всички търсачи се представиха добре. В първия тест имаше някои несъответствия въз основа на това как различните програми определят местоположението на ореолите. Някои го определят като пик на плътност, докато други го определят като център на масата. При търсене на суб-ореоли, онези, които използват подхода на фазовото пространство, изглежда, могат да открият по-надеждно по-малки образувания, но не винаги откриват кои частици в бучката са всъщност свързани. За пълната симулация всички алгоритми се съгласиха изключително добре. Поради естеството на симулацията, малките везни не бяха добре представени, така че разбирането за това как всяко детектиране на тези структури беше ограничено.
Комбинацията от тези тестове не благоприятства един конкретен алгоритъм или метод пред който и да е друг. Той разкри, че всеки обикновено функционира добре по отношение на един друг. Възможността за толкова много независими кодове, с независими методи, означава, че констатациите са изключително здрави. Знанията, които те предават за това как се развива нашето разбиране за Вселената, позволяват на астрономите да направят фундаментални сравнения с наблюдаваната Вселена, за да тестват подобни модели и теории.
Резултатите от този тест са събрани в документ, който е планиран за публикуване в предстоящ брой на Месечните известия на Кралското астрономическо общество.